Abstract
Video Query Sound Separation (VQSS) aims to isolate target sounds conditioned on visual queries while suppressing off-screen interference—a task central to audiovisual understanding. However, existing methods often fail under conditions of homogeneous interference and overlapping soundtracks, due to limited temporal modeling and weak audiovisual alignment. We propose AlignSep, the first generative VQSS model based on flow matching, designed to address common issues such as spectral holes and incomplete separation. To better capture cross-modal correspondence, we introduce a series of temporal consistency mechanisms that guide the vector field estimator toward learning robust audiovisual alignment, enabling accurate and resilient separation in complex scenes. As a multi-conditioned generation task, VQSS presents unique challenges that differ fundamentally from traditional flow matching setups. We provide an in-depth analysis of these differences and their implications for generative modeling. To systematically evaluate performance under realistic and difficult conditions, we further construct VGGSound-Hard, a challenging benchmark composed entirely of separation cases with homogeneous interference and strong reliance on temporal visual cues. Extensive experiments across multiple benchmarks demonstrate that AlignSep achieves state-of-the-art performance both quantitatively and perceptually, validating its practical value for real-world applications.
A.In-the-Wild (NEW!!!)
YouTube IDs: S6OjDU44bMo, huFzlGhhhC4, jD1gNUZ7DlI
| Original Video | Processed Left-Half Video (Silent Dog) | Processed Right-Half Video (Barking Dog) |
|---|---|---|
|

|
|
| Original Video | Processed Video |
|---|---|
|
|
|
|
B.Compare with DAVIS (NEW!!!)
Since Davis is only capable of processing 5-second audio segments, the 8-second audio samples in the test set were segmented into two intervals (0–5 seconds and 3–8 seconds) for inference. After processing, 4-second segments were extracted from each and concatenated to form the final output.
B.1.VGGSound-Clean
| Video | Mixture | Target | DAVIS | AlignSep (Ours) |
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
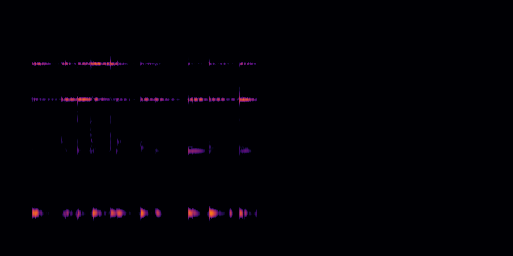
|
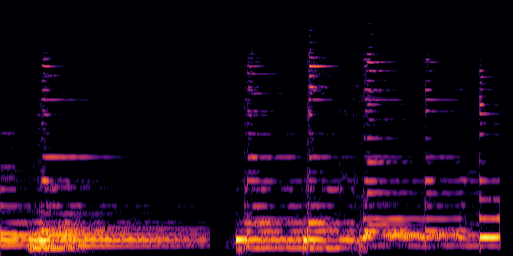
|
|
B.2.MUSIC-VGGSound
| Video | Mixture | Target | DAVIS | AlignSep (Ours) |
|---|---|---|---|---|
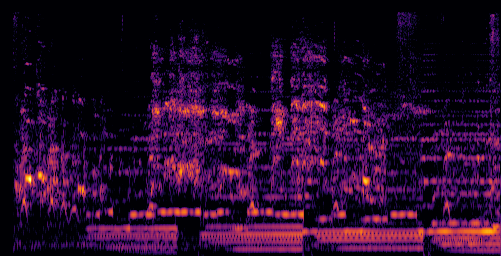
|
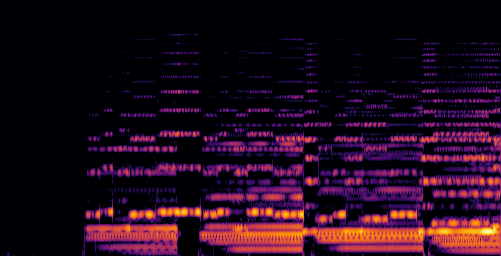
|

|
|
|
|
|
|
|
|
|
|
|
|
|
B.3.VGGSound-Hard
| Video | Mixture | Target | DAVIS | AlignSep (Ours) |
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
C.VGGSound-Silence(NEW!!!)
| Video | Mixture | Target | OmniSep | AlignSep (Ours) |
|---|---|---|---|---|

|

|

|

|
|
|
|

|

|
|
|
|

|

|
|
D.Sound Separation with Queries of Videos
D.1.VGGSound-Clean
| Video | Mixture | Target | OmniSep | AlignSep (Ours) |
|---|---|---|---|---|
|
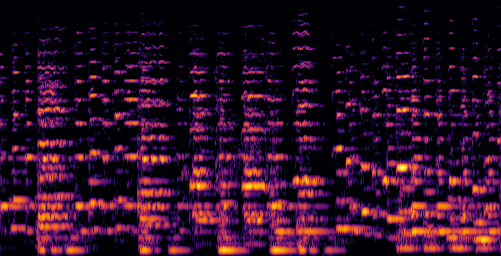
|
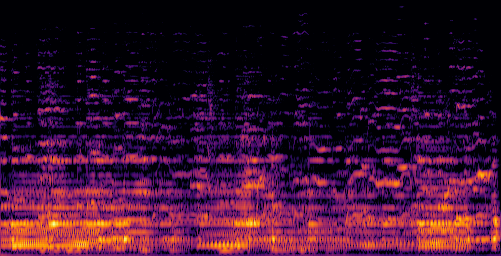
|
|
|
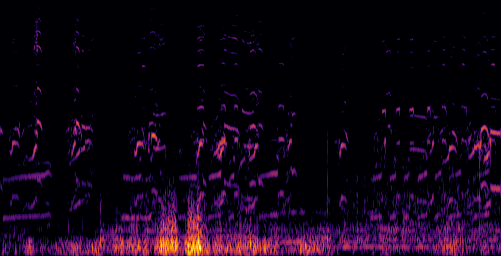
|
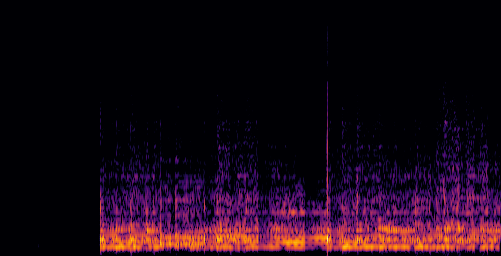
|
|
|
|
|
|
|
|
|
D.2.MUSIC-VGGSound
| Video | Mixture | Target | OmniSep | AlignSep (Ours) |
|---|---|---|---|---|
|
|
|
|
|

|
|

|

|
|
|
|
|
|
|
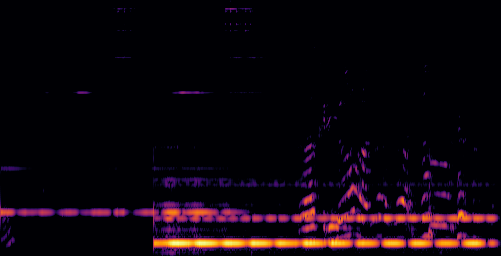
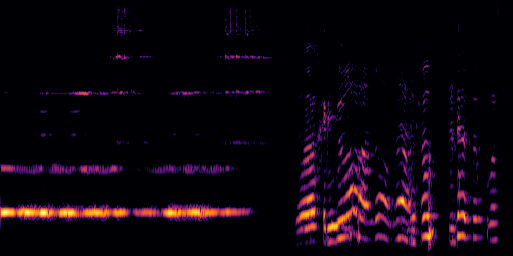
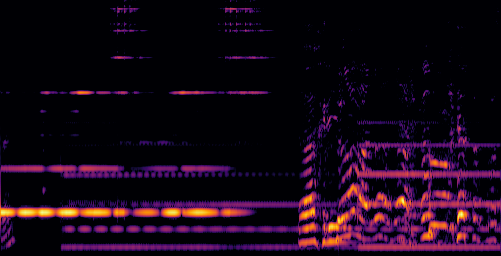
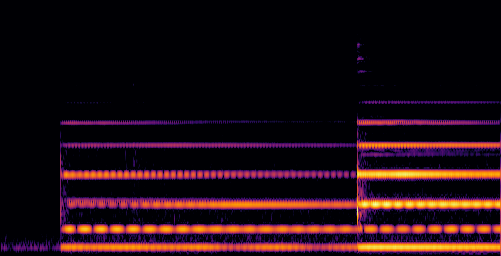
D.3.VGGSound-Hard
| Video | Mixture | Target | OmniSep | AlignSep (Ours) |
|---|---|---|---|---|
|
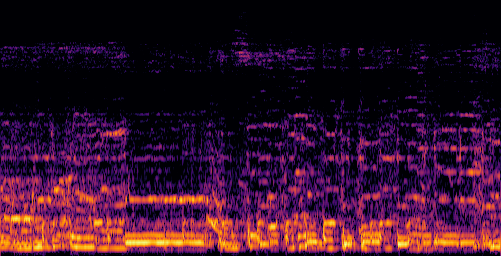
|
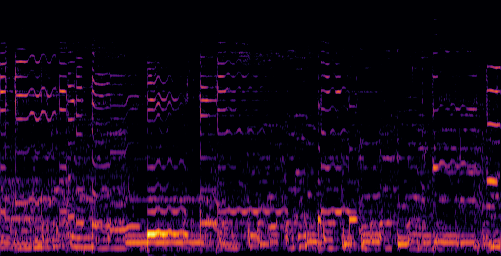
|

|
|
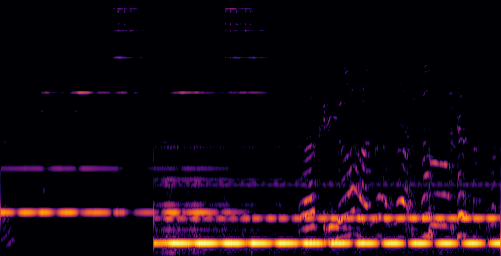
|
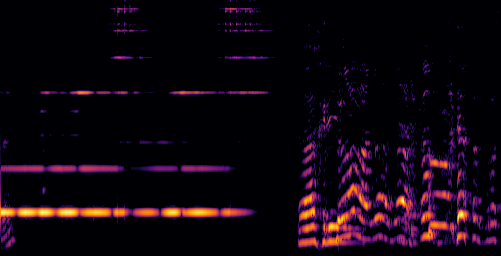
|
|
|
|
|
|

|
|
|
E. Temporally-Aligned Sound Separation
| Mixture | Target | OmniSep | AlignSep (Ours) |
|---|---|---|---|
F. Sound Separation without Holes
| Video | Mixture | Target | OmniSep | AlignSep (Ours) |
|---|---|---|---|---|
|
|
|
|
|